If you run environments with thousands of virtual servers all running very similar operating systems then it's time we talked deduplication.
Consider this... You have a VM host with 100 VMs on it. If you work for a hosting company (like I do) you likely have lots of VM hosts that look like this. Each of these VM's requires an operating system and that operating system is going to be pretty much identical across all the VMs you have on that host machine. The size varies but for this example, let's imagine that they are all Windows Server 2016 with all the updates. I happen to know that comes in at around 20GB.
So lets maths:
20GB x 100 = 2000GB or 2TB
So that means I need to use a whopping 2TB of space for operating systems before I even start with client data. Now also remember that these days the VPS market pretty much insists on using SSD storage. So to recap I am looking at 2TB of server-grade SSD plus parity before I even get started.
In 2012 Microsoft gave us their wonderful new storage architecture that allows those brave enough to use it, to perform all sorts of magical storage type functions right out of the box and one of these wonderful things is storage deduplication.
What is De-duplication?
At the most basic level, it is exactly what it says it is. It's a process which looks at the data and if it sees the same data in two locations, deletes one of them, thus using half the space than you would otherwise need for those 2 pieces of data.
How does this work in Microsoft Server 2016?
You have policies that can be configured to act on certain filetypes or exclude others. You have scheduled tasks that periodically run and perform dedupe tasks.
Dedupe scheduled tasks
Optimize - This splits files (defined in the policy) into variable sized chunks and stores them in something called the chunk store. Only single instances of unique chunks are stored in the chunk store. If the file contains 2 chunks that are the same, one is stored and one is discarded, as we already have that data and don't need a duplicate. The original files are then replaced with reparse points. These redirect any read operations of those files to the relevant chunks that make up that file.
Any application reading the filesystem is totally unaware of this process, as to it, the files that contain reparse points look just like normal files. Thus dedupe happens and space is saved.
Garbage Collection - Because the actual data is abstracted away into the chunk store and the file system you see is merely populated with reparse points, if you delete a file then you are not actually freeing up any space in your file system you are just deleting reparse points. The Garbage collection tasks run periodically to check the chunk store for chunks that have no associated reparse points. It then deletes these chunks as they are no longer needed.
Integrity scrubbing - Is the final piece of the jigsaw. This is tasked with ensuring that the filesystem is healthy. It checks for corrupt chunks and if it finds them attempts to correct any errors. It also identifies popular chunks (called hot spots) that have over 100 reparse points associated with them and duplicates them, thus splitting the load on that file and preventing performance degradation.
The regularity of these tasks is defined in the policies you create when setting up Deduplication and typically the schedule information defaulted in the policies set by Microsoft are adequate. I would really advise against changing these unless you have a specific reason to.
How Could this look in a practical setting?
Consider the example from earlier, you had 10 copies of the same 20GB's of data totalling 2TB. The system keeps just one copy of this data and in all the locations where it finds duplicates, deletes them and in their place puts a link back to the copy it has saved. Suddenly that 2TB of data is back down to around 20GB, and the cost of my VM hosts plummets, the customer gets a better cheaper product and we all skip off into the sunset.
How do I set this up?
Configuring this in Windows is very simple, the quickest way is with Powershell
Import-Module ServerManager
Add-WindowsFeature -name FS-Data-Deduplication
Import-Module Deduplication
Once this completes if you open server manager you will see File and Storage services listed as a function of that server. Dedupe can be configured there
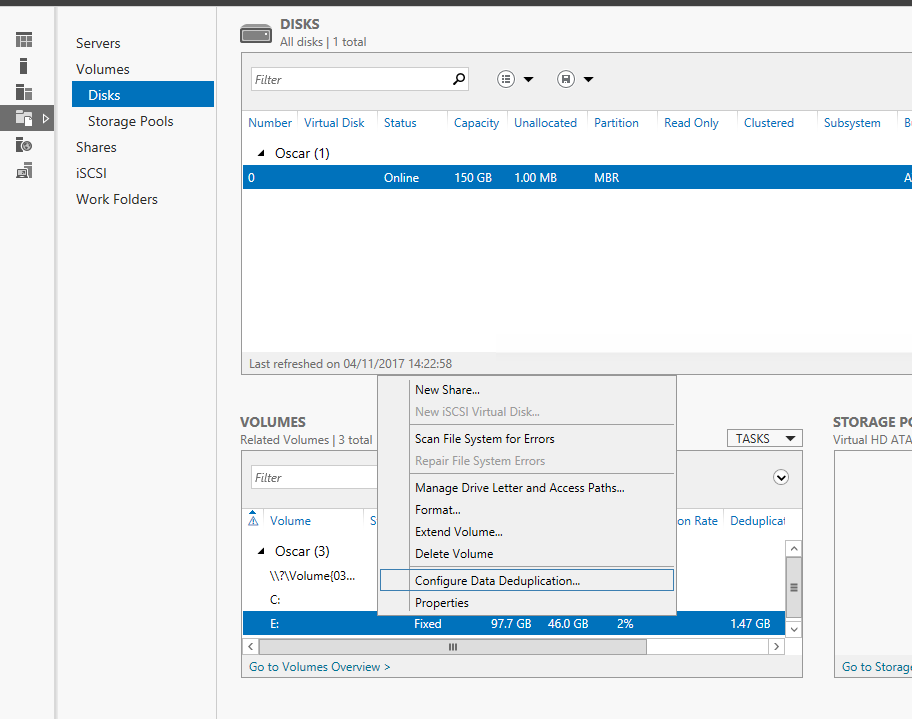
From there you can see that Microsoft has been good enough to provide us with some nice workflow specific templates to choose from.
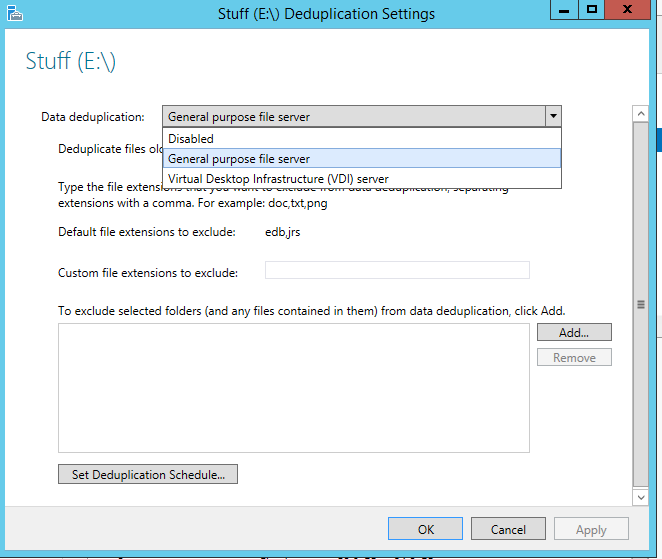
For Hyper-V environments I use VDI, I am after all hosting operating systems, then finally I need to see the job schedule.
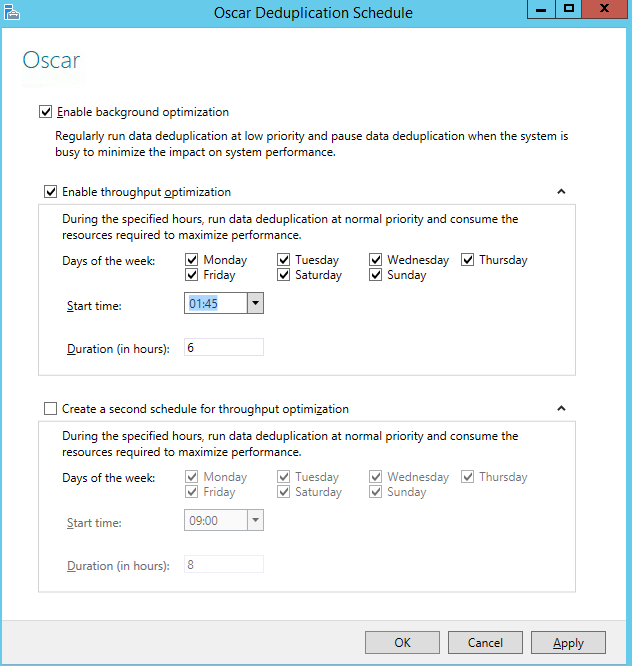
I tend to just run the schedule once a day, and it keeps on top of things but for heavier use filesystems you may want to run them more often. You can manually adjust these tasks either in the scheduled task manager or by using PowerShell.
Conclusion
When I first set this up in VDI/VPS environments I achieved 70% dedupe savings on datastores within the first 24 hours. This should be something to celebrate but If that dedupe rate dropped for any reason it would certainly take my data stores offline and the road back from that would be a very time consuming and costly. Hence the decision to put this into a live environment was a hard one. The saving grace is in terms of complex I.T systems I think the concepts that make this work are pretty simple and in VDI/VPS environments unique data is extremely rare. It really is all OS. So I made the decision to press on into live environments but at the same time also made sure we were aggressively monitoring and alerting on datastore dedupe rates. If a store drops below 50% at any time all the tech team get emails and an SMS, and the on-call technician leaps into action. I can honestly say that in 2 years that has never happened, we haven't even come close. All its done is save me piles of cash and make me look good to my boss.
In conclusion, you should all be doing this, (and probably are).